- A+
在领取数字消费券时,弹框前方拥堵,是系统出问题了么?
前言
近几年,为了促进消费,政府会发放一些消费券。有的会通过类似支付宝这样的合作商发放,也有直接使用政府APP发放。
发消费券是开心的事情,只不过没抢到的话就略有遗憾了。特别是碰到某些服务器不给力的情况,有的人就会觉得系统不太靠谱了。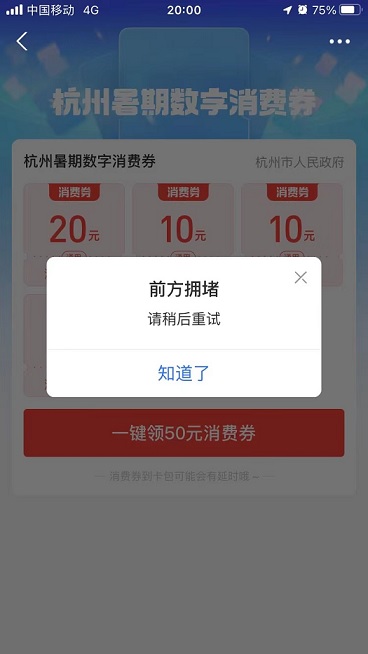
我们就从杭州数字消费券领取来分析,如何让系统经得住考验。
秒杀模型
秒杀具有时间短、并发量大的特点,秒杀持续时间可能不到一分钟。淘宝的技术可以说就是通过双十一的秒杀起家。
所以,按理说支付宝算是技术实力很强的承办方了,为什么还会出现前方拥堵呢?
实际上,这是非常正常的现象。
1. 杭州数字消费券的领取,虽然有前方拥堵的报错,但总体系统平稳,并没有崩溃。
2. 服务器不可能无限扩张,双十一的时候淘宝也会有类似的限流措施。
所以,其实这次消费券的领取是成功的。
流量
杭州的人口估计有个一千多万,假设参与的人数有100万。那么一秒钟,就得承担100万次的领取请求。但服务器是无法承担100万请求/秒的,估计能承受十万左右就差不多了。这样,如果有100万份消费券,10秒内抢完也是可以的。
在网上的百万流量秒杀系统的设计中,我们发现用户的请求实际上会有不少被限流系统拦截,这也是为什么会出现前方拥堵的弹窗。
请求到了后台,也不是简单的就可以领取了,估计服务器还得处理鉴权,风控等一系列的问题。所以,请求在系统中会被放大,这都需要服务器。
异步
此外,我们发现,领取消费券成功后,还要过段时间才能在卡券里看到。这说明消费券的实际发放其实是异步的。
这个设计非常妙。
1. 很好地避免了卡券服务被打垮的风险。
2. 领取操作简单,可以更好的优化。
3. 使用独立的集群,领取后,消费券发放集群就可以回收了。
读写
因为有异步发券的处理,所以领取操作对于系统而言,就是扣减消费券总量,增加一条用户领到消费券的记录。
读操作可以使用缓存,但写操作不能有缓存,数据需要结结实实落到数据库中。所以数据库需要能承受每秒10万的写压力。一般MySQL的写能力能到2-3万/秒,通常会用分库分表来扩展吞吐量。
扣减
增加领取记录对于分库来说,就是点插入,可以简单路由到其中一个库写入。但消费券总数是固定的,当于是一个配额,不能超卖。
所以领取时必须对配额做扣减,这就导致配额记录成为一个单点。
批量申请配额
扣减虽然是单点,但可以批量申请,然后在应用内存中扣减,一来减少对配额库的调用次数,二来也可以直接用于限流模块。
需要注意的情况是应用申请配额后崩溃,会导致部分配额丢失,出现少卖。
这种情况可以使用异步校验等办法解决。比如申请配额时留下申请记录,分发完消掉。然后将申请记录的ID写入到消费券领取记录中,如果出现异常,就可以在消费券领取记录的库中统计出实际分发的数量。
配额分仓
如果配额和记录在一个库中,消费券的领取就是一个单机事务,直接在一个数据库内完成处理。
所以,我们可以异步的,或者提前将配额分仓记录到分库中。
以上方案都是个人猜测,如有错误欢迎讨论。
其它方案
除了秒杀这种模型,是否有别的用于消费券发放的方案呢?自然是有的。比如小客车牌照,支付宝的五福,房子摇摇号,都是用的另一种方案。
摇号模型
如果想用很少的服务器来实现,那么摇号类的设计就非常适合。
我们可以开放几天的时间让用户报名,然后摇号发放。
1. 报名时间相对较长,不会出现集中的压力。
2. 风控处理可以异步。
3. 摇号分发可以异步。
假设参与的人数一样,排除重试,那么总的请求量是相等的,但时间维度却拉长很多,所以只需很少的服务器资源能搞定了。
从业务上来说,由于没有争抢,摇号对于某些硬件,网络设备较差的用户而言,也更为公平。此外,还可以利用大数据,让补贴分发给更需要的人,类似大学根据饭卡消费补贴的做法。